Noah Smith re-tweeted a tweet about Japan's price level, but in updating the results from here I still say it's the Keynesian component (not the monetary component):
Thursday, July 30, 2015
Comparing NGDP predictions with results
Here's an update of the NGDP predictions from the information transfer model (gray line), and two log linear models (the "constant long run growth" and "new post-crisis normal") in red and the Hypermind NGDP prediction market (line segments, the green segment is the implicit prediction for Q3 and Q4 based on Q1 and Q2 results and the 2015 annual growth prediction):

Here are a couple of other graphs from the original prediction post as well:


Not much commentary ... everybody is doing fine.
Updated graphics for the entropic hot potato effect
Scott Sumner's hot potato effect is a prime example of an entropic force. I wrote about this in more detail a few months ago, but I thought I'd update the graphics with a nice gif instead of a youtube video (the red line shows the median of the distribution) and add an accompanying plot of the entropy getting a shock and returning to normal:


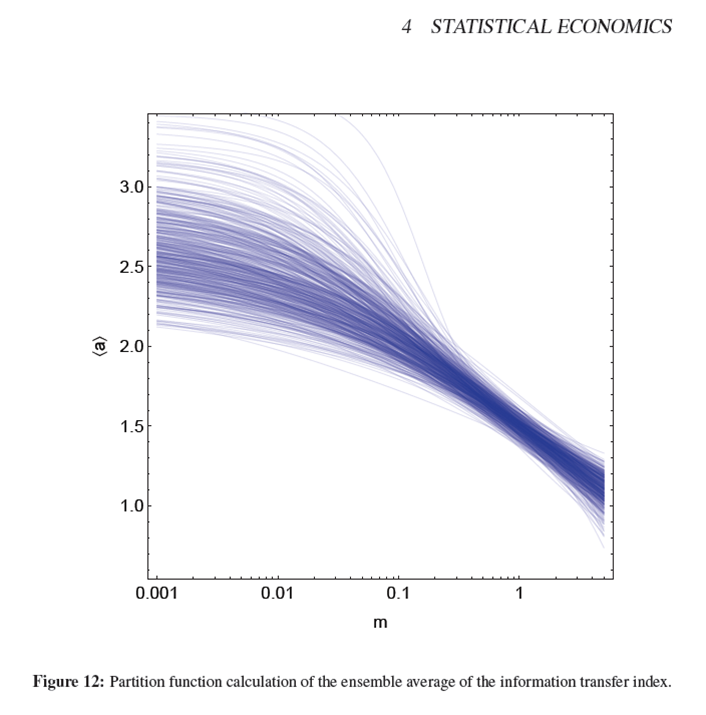
Random utility discrete choice models, partition functions and information theory

Noah Smith mentions random utility discrete choice models again, this time at Bloomberg View:
These models, which are used to predict consumer choices in a huge variety of situations, have been so accurate and successful that they are regularly cited as the canonical example of "economics that works."
As I pointed out in a comment awhile ago on his blog, there is a lot of overlap between the approach and the partition function approach to the information transfer model. In fact, one can see the information transfer macro model as a specific choice of the utility function that is proportional to log M (where M is a measure of the money supply). Entropy maximization (partition function) and utility maximization aren't necessarily completely at odds -- the differences are described in this post.
Wednesday, July 29, 2015
Paper update
I'm still working on the paper and I hope to have a draft uploaded in the next week or two (somewhere ... probably my Google Drive as a public document initially, then submission to the economics e-journal).
As it stands, the outline is:
Information equilibrium as an economic principle
1 Introduction
2 Information equilibrium
2.1 Supply and demand
2.2 Alternative motivation of the information equilibrium equation
3 Macroeconomics
3.1 AD-AS model
3.2 Labor market and Okun's law
3.3 IS-LM model and interest rates
3.4 Solow-Swan growth model
3.5 Price level and inflation
3.6 Summary
4 Statistical economics
4.1 Entropic forces and emergent properties
5 Summary and conclusion
And a couple of screenshots ...

Assuming complexity?
 |
| Now that's a complicated phase diagram. From here. |
One thing I am importing into my approach to economics from my physics background (that may well be unwarranted) is the idea that physicists apply to fundamental physics: simplicity.
In physics, we generally think the fundamental theory of everything (and unification from EM to EW) is a simplification. This is deeply connected to the idea of a greater and greater number of symmetries of the universe as you look at smaller and smaller scales, from Lorentz symmetry to super-symmetry.
However, the simplicity I am trying to bring to macroeconomic theory is based on something entirely different: the law of large numbers. This is the simplification that happens in statistical mechanics. One interesting thing is that the law of large numbers generally has to happen as N → ∞ unless you believe in significant correlations; super-symmetry does not have to happen as L → ℓp.
This philosopher of economics thinks economics is complex. These biologists think economics is complex. The physicists who made the picture at the top of this post think economics is complex. Many economists think economics is complex. So do these people.
1. Economists can't predict things very well, therefore economics is complex.
To go from this premise to concluding economics is complex requires one of two things: 1) some sort of proof or evidence that current economic theory is the only possible theory or class or theories or 2) economic theory that is correct for some other reason than predictions, but says predictions are hard (e.g. the three-body problem in Newtonian physics is complex and unpredictable, but Newtonian physics is pretty good for other reasons).
An example: Aristotelian physics didn't make good predictions about gravity. Did that mean the theory of gravity was complex and unpredictable? No, we just hadn't hit on Newton or Einstein yet.
That is to say the lack of correct predictions could be evidence your theory is wrong, not that the problem is complex.
A million 1000-variable human agents represents a billion-dimensional problem. If the state of the macroeconomy can be described by a few macroeconomic aggregates like NGDP, a couple of interest rates, inflation, money supply, (or whatever your choices are) and a handful of parameters (let's be generous and say it's 1000 variables/parameters), there has to be a massive amount of dimensional reduction [1].
If you haven't demonstrated that dimensional reduction does not happen, then the statement above is just an assumption that dimensional reduction does not happen. I'd say the onus is on you to tell us what the millions of additional relevant macroeconomic aggregates that must exist are.
This is the fallacy of the failure of imagination. Just because it is hard to imagine a simple theory of economics, doesn't mean there isn't a simple theory out there.
For example, "intelligent design" proponents (contra evolution) have an argument that some biological structures are so complex, they couldn't have evolved. That's just a failure of imagination of the particular pathway for them to have evolved.
Economists disagree because of the premise of #3: we haven't figured it out yet. The ideas behind classical mechanics weren't settled in the 1600s. That was not evidence that the future Newton's laws would be complex ... based on millions of microscopic homunculus agents.
5. There are a lot of little effects that must be considered, therefore economics is complex.
This is #2 with microeconomic or game theory effects rather than human behavior. You still have a dimensional reduction problem.
So DSGE (or whatever) is right?
...
Conclusion
Complexity is not a foregone conclusion. That doesn't mean economics isn't complex, just that you shouldn't assume complexity. In the end, you shouldn't assume simplicity, either. The best approach is to start with what you do know for sure (in the posts on this blog, essentially conservation of information) and move out from there.
My purpose here is not that the complexity of macroeconomics is a false assumption, but that we should be more aware of implicit assumptions ... and the complexity of macroeconomics is one of them.
[1] I think the correct words for this are actually "dimensionality reduction", but I don't really care. I'm not sure there is a real technical term for the fact that e.g. an ideal gas reduces from a 3N dimensional problem to a 4-dimensional problem.
Monday, July 27, 2015
Biologists' unoriginal and misguided ideas about economics
 |
| Physicists and biologists trying to fix economics ... |
Mark Thoma linked to this article on biologists wanting to get in on redefining economics with the bold, revolutionary new ideas such as "agent based modeling", "imperfect information" and "adding human behavior". It's pretty funny and I begin to see why economics "as a whole is resistant to outside incursions". I at least took the time to read up on the use of information theory in economics (and basic economics) before jumping in.
In reading the article, it becomes clear that the biologists' ideas to fix economics are both unoriginal and doomed to failure. At least if the information transfer view is correct. Some specific comments are below. I put links the supporting/elaborating material for the specific claims below at the bottom of the page.
But [mathematical formulae come] at the price of ignoring the complexities of human beings and their interactions – the things that actually make economic systems tick.
So you know for a fact that the complexities of human decision-making matter? How? Did you already model an economic system as complex human beings and discover this? Why not just show us that research?
Snark aside, this is a fundamental assumption of economics as well, so this is not only an ad hoc assumption, but an unoriginal ad hoc assumption.
The problems start with Homo economicus, a species of fantasy beings who stand at the centre of orthodox economics. All members of H. economicus think rationally and act in their own self-interest at all times, never learning from or considering others. ... We’ve known for a while now that Homo sapiens is not like that ...
Yes, we have known that for awhile, and yet very little has come of it. It's just another unoriginal idea.
In the information transfer view, H. economicus is an effective description, like a quasi-particle in physics. Once you integrate out the degrees of freedom from the micro scale up to the macro scale, the very complicated H. sapiens at the micro scale ends up looking like H. economicus at the macro scale much like the very complicated short range interaction of quarks and gluons ends up looking like a simple charged hard sphere (proton) at long range scales.
How different is a stock price crash from a wildlife population crash?
That is a figure caption and seemingly rhetorical in the article, but they're very different in the information transfer view. A school of fish can coordinate their direction to evade a predator. If an economic system coordinates, it collapses.
Wildlife population crashes are not usually due to coordination of the wildlife itself -- although population booms may lead to crashes. But in this case it is not the coordination itself that leads to a crash. The coordination of wildlife leads to a population boom that e.g. eats all the food resources, leading to starvation. In the information transfer framework, the coordination alone is the source of the fall in economic entropy that leads to a fall in price.
Wildlife population crashes are not usually due to coordination of the wildlife itself -- although population booms may lead to crashes. But in this case it is not the coordination itself that leads to a crash. The coordination of wildlife leads to a population boom that e.g. eats all the food resources, leading to starvation. In the information transfer framework, the coordination alone is the source of the fall in economic entropy that leads to a fall in price.
Taking into account [some effects] requires economists to abandon one-size-fits-all mathematical formulae in favour of “agent-based” modelling – computer programs that give virtual economic agents differing characteristics that in turn determine interactions.
This is definitely not original.
There is also a fundamental reason agent-based modeling is unlikely to be helpful. How many input parameters and variables does your agent have? 10? 100? How many agents do you have? 1000? 1,000,000? Your system is now a 100,000,000-dimensional problem.
How many equilibria does your 100,000,000-dimensional problem have? Well, if there aren't any symmetry considerations and your agents are complex enough to capture even a small fraction of the complexity of humans, you will have no idea. But that's supposed to be the point, right? We need to do bottom up simulations of agents because top down analysis doesn't work, or so the biologists (and well before them, micro-foundation obsessed economists) have said. But any particular equilibrium you find is going to critically depend on the initial conditions of your simulation. And that choice could give you any of the equilibria -- many of which probably look enough like a real economy to declare success even though you've just reduced the problem from solving an economy to finding the initial conditions that give you the economy you want.
A good example of how wrong-headed this approach is can be illustrated with protein folding. One thing the scientists who study protein folding don't do is just throw 5000 carbon, nitrogen, oxygen etc atoms in a box and turn the crank on the Schrodinger equation. You can get pretty much any structure you want this way (critically depending on initial conditions).
What they have noticed (empirically) are effective structures (protein secondary structures) that form many of the building blocks of proteins.
That is an example of dimensional reduction; the 45,000 dimensional problem of the 3D position and orientation of 5000 atoms has been reduced to a 90 dimensional problem of the position and orientation of 10 protein secondary structures.
If the information transfer model turns out to be correct, then a macroeconomy can be reduced from that 100,000,000-dimensional problem to a 20-dimensional problem (give or take). The agents -- and the extra 99,999,980 dimensions they contribute -- don't matter.
... economies are like slime moulds, collections of single-celled organisms that move as a single body, constantly reorganising themselves to slide in directions that are neither understood nor necessarily desired by their component parts
This biologist thinks economic systems are an analog of biological system. Physicists (including myself) tend to think economics reduces to statistical mechanics. Some engineers think in terms of fluid flows. I imagine a geologist would think of economics with a plate tectonics metaphor. Politicians probably think economics is all about the coordinated desires of people. Remarkable how people in a given field tend to think in terms of their field.
It would be amazing if economics just happened to reduce to an analog of a system in your field, wouldn't it?
In my defense, in the information transfer approach (if valid) it's the difference between thermodynamics (where there is a second law) and economics (where there isn't) that is the new idea. It is this difference -- that economic entropy can decrease spontaneously due to coordinated agent behavior -- that comes into play in showing the slime mold analogy is misguided. Whenever the slime mold moves as a single body you'd get recessions; whenever the individual cells do their own thing you'd get economic growth. Coordination, even emergent coordination, is economic death.
Continued reading ...
Econophysics for fun and profit [about taking on economics as an outsider]
Information theory and economics, a primer [on 'effective' H. economicus]
Coordination costs money, causes recessions
What if money was made of vinegar? [Dimensional reduction]
Against human centric macroeconomics [is human behavior relevant?]
Is the demand curve shaped by human behavior? How can we tell?
Kaldor, endogenous money and information transfer
Nick Edmonds read Kaldor's "The New Monetarism" (1970) a month ago and put up a very nice succinct post on endogenous money.
The first point is that, for Kaldor, the question over the exogeneity or endogeneity of money is all about the causal relationship between money and nominal GDP. The new monetarists ... argued that there was a strong causal direction from changes in the money supply to changes in nominal GDP ...
Endogenous money in this context is a rejection of that causal direction. Money being endogenous means that it is changes in nominal GDP that cause changes in money or, alternatively, that changes in both are caused by some other factor.
I've talked about causality in the information transfer framework before, and I won't rehash that discussion except to say causality goes in both directions.
The other interesting item was the way Nick described Kaldor's view of endogenous money
As long as policy works to accommodate the demand for money, we might expect to see a perpetuation in the use of a particular medium - bank deposits, say - as the primary way of conducting exchange. ... But any stress on that relationship [between deposits and money] will simply mean that bank deposits will no longer function as money in the same way. The practice of settling accounts will adapt, so that we may need to revise our view of what money is.
One interpretation of this (I'm not claiming this as original) is that we might have a hierarchy of things that operate as "money":
- physical currency
- central bank reserves
- bank deposits
- commercial paper
- ... etc
In times of economic boom, these things are endogenously created (pulled into existence by [an entropic] force of economic necessity). The lower on the list, the more endogenous they are. When we are hit by an economic shock stress on the system causes these relationships to break, one by one. And one by one they stop being (endogenous) money. In the financial crisis of 2008, commercial paper stopped being endogenous money.
Additionally, a central bank attempting to conduct monetary policy by targeting e.g. M2 can stress the relationship between money and deposits causing it to behave differently (which Nick reminds us is similar to the Lucas critique argument).
This brings us to an interpretation of the NGDP-M0 path as representing a "typical" amount of endogenous money that is best measured relative to M0. Call it α M0 (implicitly defined by the gray path in the graph below). At times, the economy rises above this value (NGDP creating 'money' e.g. as deposits via loans, as well as other things being taken as money like commercial paper). When endogenous money is above the "typical" value α M0, there is a greater chance it will fall (the hierarchy of things that operate as money start to fall apart when their relationship is stressed).

Another way to put this is that the NGDP-M0 path represents the steady state (or vacuum solution in particle physics) and fluctuations in endogenous money are the theory of fluctuations from the NGDP-M0 path. The theory of those endogenous fluctuations aren't necessarily causal from M2 to NGDP; however the NGDP-M0 relationship is causal both ways (in the information transfer picture).
At a fundamental level, the theory of endogenous fluctuations is a theory of non-ideal information transfer -- a theory of deviations from the NGDP-M0 path in both directions (see the bottom of this post).
Sunday, July 26, 2015
Resolving the paradox of fiat money
 |
| As the dimension of this simplex defined by the budget constraint Σ Ci = M increases, most points are near the budget constraint hyperplane ... and therefore the most likely point will be near the hyperplane. |
In his recent post on neo-Fisherism, David Glasner links to an earlier post about the paradox of fiat money -- that money only has value because it is expected to have value:
But the problem for monetary theory is that without a real-value equivalent to assign to money, the value of money in our macroeconomic models became theoretically indeterminate. If the value of money is theoretically indeterminate, so, too, is the rate of inflation. The value of money and the rate of inflation are simply, as Fischer Black understood, whatever people in the aggregate expect them to be.
The problem then becomes the problem of the "greater sucker"; rational people would only accept money because they expect they will be able to find a greater sucker to accept it before its value vanishes. But since at some point e.g. the world will end and there won't be a greater sucker, the expected value should be zero today. Note that the idea of the future rushing into the present is a general problem of expectations, as I wrote about here.
After getting a question from Tom Brown about this, I started answering in comments. Now I think the information transfer framework gives us a way to invert that value argument -- that if you don't accept money, you are the greater sucker. The argument creates a stable system of fiat currencies.
The argument starts here; I'll quickly summarize the link. If we imagine a budget constraint that represents the total amount of money in the economy at a given time being used in transactions for various goods, services, investments, etc C₁, C₂, C₃, ... Cn, then using a maximum entropy argument with n >> 1 we find the most likely state of the economy saturates the budget constraint and minimizes non-ideal information transfer (see the picture at the top of this post for n = 3). And since:
k N/M ≥ dN/dM ≡ P
we can say minimized non-ideal information transfer maximizes prices for a given level of goods and services {Cn} because P is as close to k N/M as it can be. We would think of arrangements of trust (credit) or barter exchange as less ideal (very non-ideal) information transfer than using money or some money-like commodity.
This maximized monetary value critically depends on n >> 1 -- that as many goods and services are exchangeable for whatever is being used as money as possible. This means that whoever trades their goods and services for the most widely used money gets a higher price (more ideal information transfer) for those goods and services. If I don't accept money, then I'm getting a worse deal and I'm the greater sucker. That would stabilize an existing fiat currency system because if I refuse to take money, I'd contribute to the downfall of my own personal wealth. I'd also get a worse deal in that particular transaction.
I've explained this argument in terms of rational agents. However in the information transfer framework we'd think of this argument as money allowing agents to access larger portions of state space and hence achieve higher entropy. We would think of money as a dissipative structure, like convection cells in heated water or even life itself, arising in order to maximize entropy production to move the system towards equilibrium. Convection cells only cease to exist when the water reaches a uniform temperature. Analogously, money only loses its value when every scarce resource is equally allocated among everyone (the Star Trek economy) -- the economic equivalent of heat death.
Update +3 hours:
Although the money value argument admits a rational agent explanation, the truth is that there may not be any such explanation that is valid in terms of microeconomics -- that money is an emergent structure and its effects are entropic forces. The rational explanation may be like incentives or Calvo pricing: an attempt to 'microfound' a force (effect, or structure) that only exists at the macro level. Osmosis and diffusion have no microscopic mechanism (although you could invent one, an effective force [1]) and maybe the value of money has no micro explanation that is actually true.
Footnotes:
[1] An example of a (possible) entropic force that we tend to explain with an invented micro force is gravity. We think of it as mediated by gravitons that behave similarly to photons, but it might be closer to the stickiness of glue. It is important to note that because it is an entropic macro force doesn't mean it is impossible to model as a micro force.
Update +3 hours:
Although the money value argument admits a rational agent explanation, the truth is that there may not be any such explanation that is valid in terms of microeconomics -- that money is an emergent structure and its effects are entropic forces. The rational explanation may be like incentives or Calvo pricing: an attempt to 'microfound' a force (effect, or structure) that only exists at the macro level. Osmosis and diffusion have no microscopic mechanism (although you could invent one, an effective force [1]) and maybe the value of money has no micro explanation that is actually true.
Footnotes:
[1] An example of a (possible) entropic force that we tend to explain with an invented micro force is gravity. We think of it as mediated by gravitons that behave similarly to photons, but it might be closer to the stickiness of glue. It is important to note that because it is an entropic macro force doesn't mean it is impossible to model as a micro force.
Wednesday, July 22, 2015
Compressed sensing, information theory and economics


A comment from Bill made me recall how I'd looked at markets as an algorithm to solve a compressed sensing problem before starting this blog. This is mostly a placeholder post for some musings.
The idea behind "compressed sensing" is that if what you are trying to sense is sparse, then you don't need as many measurements to "sense" it if you measure it in the right basis [1]. A typical example is a sparse image that looks like a star field: a few points (k = 3) in mostly blank space (first image above). If you were incredibly lucky, you could measure exactly the three points (m = k = 3) and reproduce the image. However, information theory tells us that we need (see e.g. here [pdf]):
m > k log(n/k)
measurements. As what you are trying to measure gets more complex, you start to need all of the points (m ~ n) which is behind the Nyquist sampling theorem. You can think of the economic allocation problem as fairly sparse -- most of the time any one person is not buying bacon (note the diagram on the upper right if you are viewing this on a desktop browser). And the compressed measurement (the m's) happens when you read off the market price of bacon [2].
There are different algorithms that take advantage of the information provided by knowing your image is sparse. One of the least efficient algorithms is linear programming. Sound familiar? That's also a very inefficient way to solve the market allocation problem.
The algorithms that solve the sparse problem also have a tendency to fail if m is too low or if you add noise to the image (second image above). Additionally, the transition from failure to success can be fairly sharp -- referred to as a Donoho-Tanner phase transition by Igor Carron. Does this tell us something about market behavior? I don't know. As I said, these are just some musings.
Footnotes:
[1] For natural images, this basis tends to be the wavelet basis. For something like our star field above, the Fourier basis works.
[2] Does a market create a basis for sparsifying an economic allocation problem?
I guess I'm back
Given that I've been posting every couple of days, empirically I'd have to say I'm back.
Tuesday, July 21, 2015
Implicit models: minimum wage and maximum entropy
One of my favorite things Paul Krugman has said is this:



Is that a realistic model? Probably not, but at least it's not implicit modeling!
Any time you make any kind of causal statement about economics, you are at least implicitly using a model of how the economy works. And when you refuse to be explicit about that model, you almost always end up – whether you know it or not – de facto using models that are much more simplistic than the crossing curves or whatever your intellectual opponents are using.
I think he's actually mentioned it a couple times. If you're not using an explicit model, the implicit model you're using is likely dumb. At the very least you're making assumptions that you haven't told us that tend to be just your gut feelings about things with frighteningly high probability.
I thought of this a couple times recently while reading some posts at Marginal Revolution (which I read to see what the latest arguments are in favor of comforting the comfortable). First, Tyler Cowen is ... scared?
[In places where the median wage is below 15 dollars], a 15 [dollar] an hour minimum wage is…shall we say…risky?
We have no idea what model Cowen is using here. And what is the risk? That aggregate supply (and thus the labor required) will fall to a level to where prices support the new wage scheme? That people will move out of Arkansas? That everything will be fine and economics 101 analysis will be discredited?
We can work out some of its properties -- for one Cowen assumes there's a significant probability that employees making less than 15 dollars per hour have sufficient market power to negotiate a wage roughly equal to their marginal product. Is this true? We don't really know for sure, but Cowen is assuming a high prior probability for it anyway.
Alex Tabarrok makes similarly implicit assumptions about the form of unobservable utility functions (and their parameter values!) in his discussion of the new proposed contractor/employee designation rules. In a sense, Tabarrok is making the same implicit assumption: that contractors have sufficient market power to negotiate the terms of their contractor status -- that they don't want to be employees. Is this true? Who knows, but Tabarrok is assuming it without telling us.
You have to let us know what your model is. If I analyze these two issues in the most naive possible way in the information equilibrium model, there's no effect from a minimum wage. I'm not saying there's no effect -- there probably is -- it's just that the model has to get more complex.
For example, if we take a maximum entropy view of the intertemporal utility maximization problem, the consideration is whether the minimum wage is comparable to the budget constraint for total compensation. Take a three period model where wages paid in each period are subject to a budget constraint w1 + w2 + w3 = W. Here, W represents the maximum profitable total pay for an employee over their career -- i.e. the total marginal product in all three periods. The typical employee is paid 0.75 W over the three periods (and most likely w1 = w2 = w3 = 0.25 W). The median wage is about 0.79 W. If we set a minimum wage at (0.8/3) W = 0.27 W in each period (i.e. higher than the median wage), we actually bump median total compensation to about 0.96 W (typically realized as w1 = w2 = w3 = 0.32 W). This is illustrated in the graphics below:


Note, this doesn't throw the other people out of the distribution -- they just all get concentrated at in the new allowed volume. I didn't show it in the picture because it made it hard to see what was going on. The distribution just shifts to higher wages, reducing the probability of occupying a wage state below 0.8 W to zero:

Is that a realistic model? Probably not, but at least it's not implicit modeling!
Saturday, July 18, 2015
Maybe Paul Romer would be interested in information equilibrium?
 |
| Cesar Hidalgo's Why Information Grows. |
This blog post is intended to see if Romer is interested in going a bit further down the rabbit hole of information theory ...
The original idea behind information equilibrium is from the physicists Peter Fielitz and Guenter Borchardt; I have applied it to economics -- thinking out loud with this blog (and likely making many mistakes as my training is in physics, not economics).
The basic idea is that if you want to say two quantities A and B are related to each other (interest rates and the money supply; capital and output) at a bare minimum the two quantities must obey a pretty simple condition based on a communication channel from A (information source) to B (information destination):
I(A) \geq I(B)
$$
At best, B can only receive all of the information A sends. This is the basis of the information transfer framework and it has two regimes: non-ideal (greater than sign) and ideal (equal sign). Ideal information transfer is also called information equilibrium and is related to the various meanings of equilibrium in economics. From the above condition, Fielitz and Borchardt motivated the differential equation:
p \equiv \frac{dA}{dB} \leq k \; \frac{A}{B}
$$
that effectively says in equilibrium fluctuations in A have to produce informationally equivalent fluctuations in B. On the left hand side, we define the derivative (the quantity that 'detects' the flow of information in Fielitz and Borchardt's paper) as an abstract price. On this blog, I've written this information transfer relationship with the shorthand $p : A \rightarrow B$ (detector/price : source → destination). Equality represents the case of information equilibrium ('economic equilibrium'), but the equilibrium solution also represents a bound on the non-ideal information transfer case (via Gronwall's inequality).
As a mathematical formalism, information equilibrium allows you to come up with a bunch of standard results in economics fairly simply (for example, this derivation of the Euler equation is pretty cool, and non-ideal information transfer let's you escape Vollrath's trilemma on Euler's theorem that Romer discussed on his blog). The intuition behind it however, that human behavior is so complex that it is indistinguishable from randomness except in situations of large scale coordination (like the panics in stock market crashes), does take a bit of getting used to given the dominant paradigm of human decision-making in traditional economics.
As a teaser, here are a few posts that assemble the Solow growth model as an information equilibrium model:
- More on Cobb-Douglas functions and information transfer: Second half of this post derives Cobb-Douglas production function from information equilibrium
- The information transfer Solow growth model is remarkably accurate: Compares the Cobb-Douglas production function to data
- The rest of the Solow model: Adding the dynamics of capital at the heart of the Solow model
- Dynamics of the savings rate and Solow + IS-LM: Adds the savings rate and interest rate
Scott, the serious flaw is expectations
 |
| Good ad hoc is building a model out of several assumptions that come together to achieve the result you want. Bad ad hoc is a single assumption that is effectively the result you want. The picture on the left is the result of a central bank setting expectations of a horse in a good ad hoc model; the picture on the left is the result of a central bank setting expectations of a horse in a ratex or other expectations-heavy model. |
Still on the light blogging/hiatus, but I am having trouble parsing this sentence from Scott Sumner:
I am increasingly confident that [the neo-Fisherites] have stumbled on something important, a serious flaw in the [New Keynesian] model.
Is the flaw the ability to get any result you want just by making different assumptions about expectations? Isn't that flaw in every macroeconomic model of expectations? Rational expectations just shifts that ability to get any result to the mechanics of the model itself (i.e. you just take off the E's in a ratex model).
Scott changes a sentence from Noah Smith to better get as his (Scott's) point at the link at the top. I'll do the same here; I'd rather Scott had said:
I am increasingly confident that [the neo-Fisherites] have stumbled on something important, a serious flaw in macroeconomics.
More here:
In the information transfer framework, I take expectations to be part of the so-complicated-it-looks-effectively-random theory of agent behavior (more about this in the context of a traffic model here).
Thursday, July 16, 2015
Infinite expectations
Mark Thoma linked to Chris Dillow, who linked to the "two-envelope problem", which links to the St. Petersburg paradox.
The St. Petersburg paradox involves the expected value of a gambling game where you put up X dollars to enter a game where the k-th time you flip a fair coin and it comes up heads, the pot grows to 2ᵏ (the casino has infinite resources). The first time it comes up tails, you get whatever is in the pot. The question is how much money X should you put up to try your hand at this game?
E = (1/2) · 2 + (1/4) · 4 + (1/8) · 8 + ...
E = 1 + 1 + 1 + ...
E = ∞
I was surprised the real answer wasn't listed in the Wikipedia article (but is available on Wikipedia):
E = 1 + 1 + 1 + ...
E = ζ(0)
E = -1/2
... so you shouldn't enter the game at any ante.
[Update: This is a bit tongue-in-cheek. But only a bit.]
Wednesday, July 15, 2015
Is economics just a collection of names?
Reading Noah Smith's post of a conversation with a finance industry insider, I realized there's another good way to see if you are dealing with a framework or not. In Noah's post there are references to Heath-Jarrow-Morton and Cox-Ingersoll-Ross. In other venues we have Diamond-Dybvig, Woodford-Eggertsson, Solow-Swan, Schmitt-Grohe and Uribe, Ramsey-Cass-Koopmans, etc.
However the use of names (and specific papers) is an indicator that there aren't general principles or ideas that make up frameworks that can be used to generate names for these models.
There are some squishy cases. For example, DSGE is sometimes referred to in terms of an "original" implementation as Kydland-Prescott (or in a specific application in Smets-Wouters), but IS-LM isn't called Keynes-Hicks as far as I know. Maybe it is. Economists frequently call it Arrow-Debreu (or ADM) instead of general equilibrium; maybe that is because the theorem wasn't constructive.
DSGE (dynamic stochastic general equilibrium), general equilibrium and the supply and demand/diagram based (partial equilibrium) models like IS-LM and AD-AS are all pretty close to being frameworks. And because of that, they tend to get called something more techincal.
Quantum mechanics isn't called Heisenberg-Schrodinger, QED isn't called Feynman-Schwinger-Tomonaga, QCD isn't called Gross-Wilczek, and the standard model isn't called Einstein-Feynman-Schwinger-Tomonaga-Gross-Wilczek-Gell-Mann-Weinberg-Glashow-Salam-Higgs-Cabibbo-Kobayashi-Maskawa (I've left some people off because I'm lazy).
There are a couple of places where a bunch of names get attached to something in physics, however. BRST quantization (Becchi-Rouet-Stora-Tyutin) and DGLAP evolution (Dokshitzer-Gribov-Lipatov-Altarelli-Parisi) come to mind. But these are specific methods or equations needed to do something (quantize a non-Abelian gauge theory and "evolve" a quark or gluon distribution from one energy scale to another, respectively).
Now this isn't a hard and fast rule and there are probably many exceptions out there. Newtonian physics is one that immediately comes to mind (the technical term is [classical] mechanics, though). But that may just reinforce my point. Newton came along in a time when advances in physics were defined by the people describing them, which, as I describe in my link above, is where I see macroeconomics. "Newtonian" may just be a hold-over from a framework-less time as we don't refer to Einsteinian or Heisenbergian physics (for the relativistic and quantum corrections to Newton's theory).
Don't read this as a criticism -- this is not a bad thing, and I hope to have my name in one of those lists some day. It really means economics is in an exciting time, a period of discovery and flux. Some of those names at the top of the post will be in textbooks for hundreds of years.
Monday, July 13, 2015
Macro-finacial economics puzzles: 3 out of 10 ain't bad
Noah Smith linked to this paper by Xavier Gabaix [pdf] again the other day which reminded me that I had a draft post I was working on before taking a short break from blogging. For those suffering from information transfer economics withdrawal (all zero of you), here it is ...
Noah Smith linked to this paper by Xavier Gabaix [pdf] that succinctly described 10 "puzzles" of financial economics (and how they could be solved by considering the risk of rare disasters). I'd like to point out that the information transfer model has its own solution to a few of them (not entirely unrelated as 'rare disasters' could be called 'rare non-ideal information transfer'):
3. Excess volatility puzzle: Stock prices seem more volatile than warranted by a model with a constant discount rate (Shiller 1981).
Any kind of excess volatility (exchange rates) could result from the combination of non-ideal information transfer and investors having the wrong model for pricing an asset as I discuss here.
4. Aggregate return predictability: Future aggregate stock market returns are partly predicted by price/dividend (P/D) and similar ratios (Campbell and Shiller 1998).
The aggregate stock market can be considered to be made up of many individual stocks with a distribution of different (and changing) information transfer indices (hence different returns from period to period). This distribution (given a large number of companies) is roughly constant and the prices are based on fundamentals (hence things like book value or P/D ratios) with random fluctuations. Effectively this is applying the partition function approach to this model of individual stocks.
Another way to put this is that in the same way the aggregate economy (roughly) follows the quantity theory of money even though it's made up of many sectors each doing very badly, very well or just kind of muddling through, stocks have aggregate predictable returns even though individual companies come and go.
6. Yield curve slope puzzle: The nominal yield curve slopes up on average. The premium of long-term yields over short term yields is too high to be explained by a traditional RBC model. This is the bond version of the equity premium puzzle (Campbell 2003).
In the information transfer model, the difference between long term and short term interest rates (on average) is mostly due to central bank reserves. No reserves and the premium would be smaller. There is a secondary effect where short term rates are given to more serious bouts of non-ideal information transfer, hence tend to fall below their "information equilibrium" value more often than long term rates.
Thursday, July 2, 2015
Summertime
I am going to take short break from blogging (probably until August). I'll probably answer comments. For new readers, this is a good time to go through the old posts if you'd like. Keep in mind there are two major phase transitions in the blog. One happens in June of 2013, where I slowly figured out the relationship between the IT index and the macro model, starting about here:
The second happens around February 2014 where I figured out the monetary base doesn't produce a good inflation model:
Just keep those dates in mind. Most of the posts before June 2013 don't have anything to do with anything that follows except for the basics of supply and demand.
If you'd like something to ponder during the hiatus, I mentioned in a footnote here:
If you'd like something to ponder during the hiatus, I mentioned in a footnote here:
[Secular stagnation] could be visualized as an economy taking longer and longer to explore (via dither) the nearby state space. A possibility is that not only is the volume of states growing, but the dimension is growing as well.
Here is a graph of the rate of change of volume for a "log(R)-sphere" -- a n-sphere of radius R with dimension n = log R:

The volume formula is:
$$
V_{\log R}(R) = \frac{\pi^{\log R/2}}{\Gamma (\frac{\log R}{2} + 1)} R^{\log R}
$$
A couple things to note. R here would be analogous to the monetary base (minus reserves, per the link above), so that log R is approximately (proportional to) time.
If we make the assumption of an approximately constant rate of innovation (like mutations in DNA), then new products/services appear at roughly a constant rate -- therefore the dimension of the economic space would also be proportional to log R (each bit of stuff we can spend money on is a new dimension in the optimization problem).
Increasing the dimension (from some dimension n to some dimension n* > n for some n) of a sphere at constant radius decreases its n-volume (the gamma function in the denominator always wins eventually). So you can imagine increasing n at some rate and increasing R (which always causes a sphere to increase in n-volume) at some rate could lead to a case where there is a decreasing growth rate of the volume.
Wednesday, July 1, 2015
The Sadowski Theory of Money
Tom Brown mentioned Mark Sadowski has another post over at Marcus Nunes' blog; it includes what might be the most hilarious monetarist volley yet. But intriguingly it points to an opening for full scale acceptance of the information transfer model. I'll call it the Sadowski Theory of Money (STM). Mark first shows us a plot of the monetary base (SBASENS) and CPI. I have no idea what happens next or in the follow up post because this is effectively what he shows:

When I was back in college in the 1990s, I once was watching some local cable access program late at night. In it there was some suited presenter -- likely at one of the Helium wells out near Amarillo -- going through a model of how Helium escapes from underground traps. It was quite detailed. In the end, he came out with the result that the measured levels of Helium meant that the Earth couldn't be older than 6000 years old. I started weeping.
Regardless of how adept people are at mathematics or statistics, it does not indicate of how good they are at the pursuit of knowledge. The reasons range from being blinded by ideology or religion to a lack of curiosity about the results they produce. I think Mark is part of the former.
I'm not quite as emo as I was back in college, so the reason I couldn't get past the first graph in Mark's post was that I busted out laughing. If you zoom out from the graph, you can see why:

Over the course of the history of economic thought (starting from Hume and continuing through Milton Friedman and beyond), there was a theory that was called the Quantity Theory of Money. In its most rudimentary form, it said that increases in the amount of money (say, the monetary base MB) led to an increase in the price level (P),
P ~ MB
log P ~ log MB
log P ~ k log MB
And we are living in a new modern era of monetary policy effectiveness, so only data since 2009 is relevant! So Mark studies the correlation between log P and log MB, scaling the variables and the axes in order to derive a value for k. An excellent fit is given by [1]
log P ~ 0.125 log MB
"Monetary policy is (a tiny bit) effective!" Mark shouts from the hilltops (after doing some rather unnecessary math I guess so he doesn't have to come out and state the equation above), "We are governed by the Sadowski Theory of Money!" We can see how Mark has thrown hundreds of years of economic thought out the window by putting the STM on this graph of the QTM from David Romer's Advanced Macroeconomics (along with a point representing the US from 2009 to 2015):

Ok, enough with the yuks. Because in truth Mark Sadowski might be my first monetarist convert. That's because the model
log P ~ k log MB
is effectively an information transfer model (I had the codes ready to fit that data above) ... but just locally fit to a single region of data. You could even find support to change the value of k, allowing k to change from about 0.763 to about 0.125 [2] going through the financial crisis. Here is the fit to 1960-2008:

You're allowed to do what Mark did in his graph in the information transfer model. But then you have to ride the trolley all the way to the end. That change in k from 0.763 to 0.125 over the course of the financial crisis would be interpreted as a monetary regime change. Let's explore what happened to the relationship bewtween a variation in P and MB:
δ (log P) ~ δ (k log MB)
δP/P ~ k δMB/MB
So the fractional change in P (inflation) is k time the fractional change in MB (monetary base growth rate). Between 2008 and 2010, according to the STM, that dropped by a factor of about 0.763/0.125 ~ 6. That is to say monetary policy suddenly became six times less effective than it was before the financial crisis.
Before 2008, a 100% increase (a doubling) of the monetary base would have lead to a 70% increase in the price level. After 2008, it leads to a 9% increase in the price level.
Monetary policy suddenly becoming far less effective ... sounds exactly like a liquidity trap to me.
The Sadowski Theory of Money is an information transfer model with a sudden onset of a liquidity trap during the financial crisis [3].
Footnotes:
[1] There is a constant scale factor for the price level of about 84.1 for the CPI given in units of 1984 = 100; I will call it a "Sadowski" in honor of the new theory and its discoverer. The equation is shown in the graphs.
[2] Note that k = (1/κ - 1) so k = 0.763 is κ = 0.57 (near the QTM limit of 1/2) and k = 0.125 is κ = 0.89 (near the IS-LM limit of 1).
[3] Of course, 'M0' (MB minus reserves) works best empirically and has no sudden onset of the liquidity trap, but rather a gradual change from the 1960s to today.
Paul Krugman's definition of a liquidity trap
In the discussion in this post, I mentioned how I viewed the liquidity trap and zero lower bound:
[the phrase "zero lower bound"] is used to mean the appropriate target nominal interest rate (from e.g. a Taylor rule for nominal rates, or estimate of the real rate of interest after accounting for inflation) is less than zero (i.e. because of the ZLB, you can't get interest rates low enough). I've usually stuck to [that] definition ...
I am happy to report that it is essentially the same as Paul Krugman's definition [pdf] of a liquidity trap:
Can the central bank do this? Take the level of government purchases G as given; from (2) and (5) this will tell you the level of C needed to achieve full employment; (4) will tell you the real interest rate needed to get that level of C; and since we already have both the current and future price levels tied down, this implies a necessary level of the nominal interest rate. So all the central bank has to do is increase the money supply until the rate is at the desired level. But what if the required nominal rate is negative? In that case monetary policy can’t get you there: once the interest rate hits zero, people will just hoard any additional cash – we’re in the liquidity trap.
Bold emphasis was italic emphasis in the original. As Paul Krugman says: the required (target) nominal rate is negative. The observed nominal rate is unimportant except as an indicator of the point where people hoard cash.
H/T to Robert Waldmann for pointing me to the reference.
Subscribe to:
Posts (Atom)